Фирмы Ipsilon и Toshiba в своих решениях IP Switching (IP-коммутация) и Cell Switch Router (маршрутизатор с коммутацией ячеек, CSR) основываются на концепции идентификации потока трафика (traffic flow).
Решения этих фирм предназначены для сетей АТМ. В их основе лежит механизм коммутации пакетов “на лету”. Такая коммутация происходит на втором уровне модели OSI и не требует применения протоколов верхних уровней. Некоторым недостатком этих технологий является то, что они поддерживают лишь ограниченное число сетевых протоколов. Так технология фирмы Ipsilon поддерживает протоколы
IP и IPX, а технология фирмы Toshiba поддерживает только протокол IPX.Основой этих технологий является потоковая организация передачи данных. Под потоком понимается набор пакетов от конкретного отправителя к конкретному получателю. Подразумевается, что речь идет не об одном-двух пакетах, то есть поток не должен быть слишком мал. Предполагается, что поток существует достаточно длительное время, иначе нет смысла его выделять. Поток может быть как единичным, так и групповым. Основной характеристикой потока является его время жизни. Поэтому применительно к рассматриваемым технологиям весь трафик можно разделить на две категории:
Обе технологии полагаются в своей работе на использование специальных (фирменных) протоколов для распространения информации (извещения) о потоке между коммутаторами в центре сети.
Технология фирмы Ipsilon использует протокол Ipsilon Flow Management Protocol (протокол управления потоком, IFMP), а технология фирмы Toshiba - Flow Attribute Notification Protocol (протокол извещения об атрибутах потока, FANP). Данные протоколы обеспечивают взаимодействие коммутаторов на пути следования графика.
Идентификация потока трафика выполняется по заданным критериям (тип приложения, количество пакетов и т. д.). После идентификации коммутатор устанавливает коммутируемый путь и его соседи через протокол извещения информируются о потоке. Такой коммутируемый путь можно отождествить с виртуальным соединением АТМ.
При использовании этих протоколов остальные коммутаторы в пути получают информацию об определенном потоке и устанавливают дополнительные коммутируемые пути. При прекращении потока коммутируемый путь разрывается каждым коммутатором индивидуально. Это происходит после истечения определенного периода неактивности.
Следует отметить, что эти два решения обеспечивают коммутацию “на лету” только для потокового трафика. Весь остальной трафик будет обрабатываться с задержкой, присущей традиционной маршрутизации.
Говоря об актуальности предложенных технологий, необходимо учитывать исследования, проведенные фирмой Ipsilon, которые показали, что более 80 % передаваемых пакетов и 90 % передаваемых байтов могут быть квалифицированны как потоки и, следовательно, преимуществами коммутации “на лету” можно пользоваться очень широко. По заявлениям той же фирмы производительность, обеспечиваемая ее коммутаторами, в пять раз превосходит ту, что могут обеспечить традиционные маршрутизаторы.
Анализируя недостатки метода потоковой коммутации, следует помнить, что обе технологии устанавливают уникальный виртуальный канал для каждого потока, и коммутатор способен обслуживать до 3000 потоков в секунду, так что в большой сети количество потоков может превысить число записей, доступных в таблице виртуальных каналов коммутатора. Кроме того, важно учитывать, что эффективность данных технологий сильно зависит от характера трафика.
Технология 3Com FastIP ориентирована на небольшие сети. Сразу отметим, что для работы этой технологии требуется изменение драйверов сетевых адаптеров на рабочих станциях и северах. Но с другой стороны, технология позволяет оставить практически без изменений существующую базу установленного оборудования (коммутаторы и маршрутизаторы).
Кроме того, для работы этой технологии обязательно требуется наличие маршрутизатора. Маршрутизатор может быть как специализированным устройством, так и коммутатором с поддержкой маршрутизации. Фирмой 3Com рекомендован именно последний вариант, который является более предпочтительным, если учесть высокую стоимость маршрутизаторов и большое число уже установленных коммутаторов CoreBuilder 2500 и CoreBuilder 6000. Встроенная в эти коммутаторы поддержка маршрутизации полностью удовлетворяет требованиям, предъявляемым технологией 3Com FastIP к маршрутизатору.
Решение фирмы 3Com отводит активную роль самим рабочим станциям и серверам, запрашивающим те или иные сетевые услуги. В основе данного решения лежат три стандарта: Next Hop Resolution Protocol (NHRP), IEEE 802.1Q/IEEE 802.1p и Ipsilon Flow Management Protocol (IFMP). Основным является протокол NHRP, который был модифицирован фирмой таким образом, чтобы он мог работать в
обычной широковещательной сети (изначально протокол был ориентирован на сеть АТМ).Принципы работы этой технологии очень просты. Любая станция может взаимодействовать с другими станциями в одной IP-подсети (или виртуальной сети) посредством обычных коммутаторов. В этом случае технология 3Com FastIP не задействуется. При необходимости передачи данных в другую подсеть пакеты должны посылаться на обычный маршрутизатор. В этом случае станция направляет запрос протокола NHRP маршрутизатору. Маршрутизатор может либо игнорировать этот запрос (например, из соображений безопасности), либо передать этот запрос станции-адресату. В этом случае станция-адресат попытается установить чисто коммутируемое соединение со станцией-отправителем (инициатором соединения). Если между ними существует маршрут, проходящий исключительно через коммутаторы, то попытка будет успешной, и весь последующий трафик будет передаваться в обход маршрутизаторов (рис. 1).
Защита данных в технологии 3Com Fast IP достигается за счет того, что вначале запросы NHRP от станций должны пройти через маршрутизатор, находящийся на пути передачи данных. В распределенных сетях, в которых необходимо обеспечить повышенную безопасность, маршрутизатор можно настроить так, чтобы он блокировал NHRP-запросы, адресованные определенной станции или полученные с той или иной станции. Если маршрутизатор начнет блокировать такие запросы, то выстроить кратчайший путь передачи через коммутаторы не удастся и трафик будет передаваться через блокирующий маршрутизатор и, возможно,
другие маршрутизаторы на пути следования, т.к. коммутаторы 3Com CoreBuilder 2500/6000 могут выполнять начальную маршрутизацию и последующую коммутацию данных.Первая коммерческая реализация технологии FastIP появилась в конце 1997 года в виде бесплатно распространяемых драйверов для наиболее широко используемых сетевых адаптеров фирмы 3Com. Кроме того, 3Com обещает выпустить драйвер с поддержкой своей технологии для сетевых адаптеров фирм Intel и SMC (адаптеры этих фирм наиболее популярны). Драйвера и утилиты, необходимые для реализации технологии 3Com Fast IP на практике, можно либо получить вместе с сетевыми адаптерами фирмы 3Com, либо загрузить с домашней страницы фирмы 3Com (www.3com.com).
Для упрощения использования программного обеспечения 3Com Fast IP можно применить программные комплексы управления сетями: Microsoft SMS, Symantec Norton Administrator, Novell ManageWise и т. д.
Кроме того, ожидается выход новой версии технологии FastIP с существенными дополнениями. В ней будет расширен спектр поддерживаемых сетевых адаптеров и введена поддержка назначения трафику приоритетов. Дополнительно будет реализована концепция Proxy FastIP, при которой отвечать на запросы будет не сама станция, а ближайший к ней коммутатор. В результате администраторы получат большую гибкость, так как они смогут использовать сетевые адаптеры не только фирмы 3Com (при наличии такого коммутатора от сетевых адаптеров не будет требоваться обязательная поддержка FastIP). Кроме того, это позволит повысить степень защищенности информации, поскольку коммутатор сможет следить за проходящим через него графиком.
Технология FastIP удовлетворяет требованиям, выдвигаемым такими технологиями последнего поколения, как АТМ и Gigabit Ethernet. Так как технология FastIP достаточно успешно решает свою основную задачу — устранение узких мест в сети, связанных с маршрутизацией данных, — она способствует поддержке трафика на гигабитных скоростях. Таким образом становится возможным передавать данные со скоростью канала связи между подсетями. Изначально технология FastIP ориентировалась на применение в средних по размеру сетях, однако, учитывая постоянную тенденцию укрупнения сетей, фирмы 3Com, IBM и Cascade объявили о разработке общего механизма взаимодействия, который позволит создавать сети с коммутацией
третьего уровня практически любого размера.
Фирма Cisco Systems предложила две различные технологии, реализующие правило “коммутировать по возможности, маршрутизировать по необходимости”: CiscoFusion и
Cisco NetFlow Switching.Технология CiscoFusion позволяет расширить оригинальную архитектуру маршрутизатора Cisco 7000, отделив вычисление маршрута от передачи пакетов. В технологии CiscoFusion вычисление маршрутов для многоуровневых коммутаторов Cisco (например Catalyst 5000) производится маршрутизаторами серии 7000.
Эти маршрутизаторы передают информацию о маршруте многоуровневым коммутаторам, которые затем должны ее сохранить. Это позволяет коммутаторам самостоятельно поддерживать функции третьего уровня вместо того, чтобы передавать весь трафик между подсетями, используя маршрутизатор. Коммутаторы используют специальное аппаратное обеспечение и за счет этого достигают лучшей производительности на третьем уровне, чем маршрутизаторы.
Независимо от технологии CiscoFusion фирма Cisco предлагает технологию NetFlow Swtiching, которая призвана повысить производительность маршрутизаторов серии 7000 с программным обеспечением Cisco IOS. Это достигается выделением потоков трафика, которые затем обрабатываются более эффективно и с максимальной скоростью.
Первый поступивший пакет потока обрабатывается с использованием традиционной маршрутизации: просмотр таблицы маршрутизации, проверка правил фильтрации и т. д. После идентификации потока все последующие пакеты данного потока обрабатываются ускоренно за счет своего рода кэширования: время, необходимое для выполнения обычных операций маршрутизации, сокращается, так как они уже частично выполнены (запись в таблице маршрутизации найдена, правила проверены и т. д.).
В настоящее время технология NetFlow Switching поддерживает только протокол IP. Поддержка протокола IPX анонсирована фирмой. Данная технология работает независимо на каждом маршрутизаторе. Если данные проходят через несколько маршрутизаторов, то каждый из них будет выделять и идентифицировать собственный поток. Эта технология не предусматривает обмена служебной информацией о потоках между отдельными маршрутизаторами.
Помимо описания самой технологии, интересно привести конкретный пример, где ее использование полностью оправдано. В качестве такого примера давайте рассмотрим задачу построения распределенной сети организации, охватывающей несколько крупных сетевых центров (например, это может быть сеть провайдера услуг связи).
Выбор наиболее подходящей сетевой технологии для распределенной сети зависит от нескольких основных параметров. Во-первых, она должна быть широко доступна и проверена временем. Во-вторых, следует проанализировать, достаточно ли пропускной способности, обеспечиваемой данной технологией. В-третьих, необходимо обеспечить минимальный уровень потерь данных, так как такие потери приводят к повторным передачам. Даже если повторной передачи не происходит, потери все равно неприятны, так как, например, при передаче аудио- и видеоинформации они приводят к
искажению изображения. Кроме того, желательно, чтобы сетевая технология могла гарантировать небольшую и предсказуемую задержку.Важным фактором также является возможность самостоятельно обнаруживать и устранять ошибки в физических каналах передачи. Это связано с тем, что обмен информацией играет все большую роль в жизни организаций и лишиться возможности такого обмена даже на непродолжительное время означает понести немалые убытки. Кроме того, существенно возросла скорость передачи информации по сети, поэтому накладные расходы, связанные с организацией самовосстановления работы сети, ощущаются не так сильно. Относительная стоимость самих линий связи (сравнительно с теми потерями, к которым могут привести нарушения в обмене информацией) снижается. Так что, как правило, дополнительные расходы на обеспечение повышенной надежности сети и возможные потери от простоя вполне сопоставимы.
Большинство предъявленных требований могут быть удовлетворены при использовании маршрутизаторов фирмы Cisco Systems и ее технологии NetFlow Switching. Необходимость применения технологии маршрутизации при построении сети обусловлена следующими важными соображениями. Прежде всего маршрутизация позволяет решить такую типичную задачу как ограничение широковещания. Кроме того, маршрутизаторы часто используются в качестве брандмауэров (защитных экранов) между сетью организации и Internet. При этом они действуют как фильтры пакетов, просматривая адресную информацию в заголовке пакета и сопоставляя ее со списком управления доступом. Далее маршрутизаторы могут применяться для фильтрации графика по каналам городской сети, передавая через нее только избранный трафик, что, в частности, позволяет снизить плату за использование этих каналов. И, наконец, технология маршрутизации прошла проверку временем и доказала свою полную пригодность для построения крупных сетей.
В основу предлагаемого фирмой Cisco решения заложено использование технологии SONET (скорость передачи 155 Мбит/с) на физическом уровне, поверх которой работает протокол IP. По заявлениям фирмы такой подход позволяет в два раза сократить накладные расходы на передачу данных по сравнению с технологией АТМ. Такой способ передачи информации все прочнее завоевывает позиции в мире сетей. Это связано с доминирующим положением протокола IP и растущей тенденцией его применения для передачи всех типов трафика (голоса, видео и данных) по сети.
Для повышения надежности и скорости передачи данных предлагается использовать так называемую связную топологию сети, в который все маршрутизаторы связаны друг с другом. Это позволяет находить оптимальные пути передачи трафика, исключая его обработку промежуточными маршрутизаторами, что в сочетании с технологией Cisco NetFlow Switching приводит к значительному снижению задержек. Предлагаемое решение сочетает в себе высокую скорость передачи, относительно невысокую стоимость, простоту реализации и поддержки, устойчивость к сбоям и отказам, а также возможность масштабирования.
Следует отметить, что если в технологиях фирм Ipsilon и Toshiba поток определяется конечными устройствами, взаимодействующими друг с другом, то в технологии Cisco NetFlow Switching он определяется каждым маршрутизатором в отдельности на протяжении всего пути следования трафика.
Технология SecureFast Virtual Networing (SFVN) фирмы Cabletron основана на комбинации коммутации и маршрутизации. Коммутация в коммутаторах Cabletron SmartSwitch обеспечивается встроенной функцией коммутации третьего уровня, а маршрутизация поддерживается специальным сервером маршрутизации.
Каждый коммутатор SmartSwitch в процессе своей работы узнает физические и сетевые адреса устройств, подключенных к его портам. Затем коммутатор определяет соответствие физических и сетевых адресов данных устройств. В результате решение о передаче принимается по схеме традиционной коммутации, но на основе сетевого адреса.
Коммутаторы SmartSwitch опираются на сервер маршрутизации для определения оптимального коммутируемого пути между двумя устройствами, что позволяет передавать данные с максимально возможной скоростью. Когда передача необходимых данных завершается, коммутируемый путь между этими устройствами закрывается. При этом повышается уровень безопасности в сети, так как коммутируемый путь между устройствами не может быть установлен без санкции сервера маршрутизации.
Отличительной особенностью технологии SFVN является процесс обработки широковещательного графика. Широковещательные пакеты, запрашивающие статус устройств в сети, перехватываются коммутатором и не передаются далее по сети. После этого коммутаторы используют сервер маршрутизации для разрешения запросов (например запросов протокола ARP).
При получении широковещательных пакетов с объявлениями коммутатор будет передавать их только тем устройствам, которые нуждаются в них. Например, сообщения протокола маршрутизации RIP IP будут получать только маршрутизаторы.
Технология SFVN устраняет необходимость формирования традиционных виртуальных сетей, так как не требует выделения подсетей — все устройства могут находиться в одной IP-подсети. При внедрении этой технологии в существующую сеть на базе протокола IP администратору может потребоваться изменить маску подсети и переопределить маршрутизатор по умолчанию. То, какие именно изменения потребуются, зависит от используемой схемы
IP-адресации.Технология SFVN имеет много общего с технологией Multiprotocol Over АТМ (МРОА), которая рассматривается далее. Обе технологии используют сервер маршрутизации и устанавливают логическое соединение между абонентами. Кроме того, они не зависят от используемого сетевого протокола.
Недавно фирма Cabletron объявила о своем намерении согласовать с фирмой Ipsilon технологии SFVN и IP Switching. Если такое партнерство станет реальностью, технология SFVN будет использоваться в промышленных сетях, а технология IP Switching — для организации связи отдельных SFVN-сетей.
Технология Multiprotocol Switched Services (MSS) реализует одно из направлений, продвигаемых фирмой IBM для развития АТМ, и ориентирована на применение в центре сети. Технология MSS как бы выносит функции маршрутизации на края сети и опирается на два основных компонента: MSS-сервер и MSS-клиент.
MSS-сервер действует как сервер маршрутизации и отвечает за вычисление маршрута. Кроме того, он выполняет функции сервера эмуляции LANE и поддерживает виртуальные сети. MSS-сервер может иметь две реализации: централизованную, при которой он устанавливается на одном коммутаторе АТМ, или распределенную, при которой сервер устанавливается на
нескольких коммутаторах. MSS-сервер поддерживает следующие стандарты: NHRP, LANE и МРОА.MSS-клиенты могут располагаться на граничных коммутаторах АТМ, на рабочих станциях или на серверах, напрямую подключаемых к сети АТМ. MSS-клиент выполняет передачу кадров и фильтрацию, предоставляет функциональные возможности технологии LANE обычным клиентам и кэширует информацию о получателе, предоставленную MSS-сервером.
Если трафик необходимо направить между двумя MSS-клиентами в различных подсетях и виртуальных сетях, то один из MSS-клиентов проверяет свой кэш на наличие информации о пути. Если такая информация есть, то используется однопереходная маршрутизация (устанавливается прямое виртуальное соединение, которое и служит единственным переходом) через сеть АТМ. Если ее нет, то трафик передается к MSS-серверу, который идентифицирует и устанавливает необходимые виртуальные каналы между двумя конечными точками. Функции MSS-клиента могут поддерживаться на всех конечных устройствах. При этом все конечные устройства должны напрямую подключаться к сети АТМ.
Данное решение основано на фирменном алгоритме обмена меток ( label swapping ). Новая технология направлена на расширение возможностей центральных маршрутизаторов распределенной сети.
Каждый маршрутизатор с поддержкой технологии тег-коммутации (Tag Switching Router, TSR) первоначально формирует внутренний образ сетевой топологии , используя стандартые протоколы марщрутизации (OSPF, BGP, EIGRP). После заполнения таблиц маршрутизации каждый TSR локально генерирует для каждого маршрута так называемую меткую Метка - это короткая строка фиксированной длины. Небольшой размер строки позволяет ускорить и упростить поиск в таблице маршрутизации. Каждая метка может соответствовать одному маршруту или их совокупности. Эти локольно генерируемые метки распространяются между соседними TSR с помощью фирменного протокола TDP ( Tag Distribution Protocol). Как только пакет поступает на граничный TSR, ему присваивается своя метка, и затем он передается следующему TSR на данном маршруте. Метка имеет смысл только в области действия маршрутизаторов с технологией Tag Switching. Привыходе пакета из этой области метка изымается.
Маршрутизаторы, расположенные внутри действия Tag Switching, принимают решения о маршрутизации основного трафика в зависимости от метки. После получения пакета маршрутизатор корректирует метку и отправляет ее следующему TSR. Если полученный пакет содержит метку, о которой нет информаци или метка соответсвует нескольким маршрутам, то данный TSR будет выполнят маршрутизацию традиционным способом.
Метка может размещаться: после заголовка кадра второго уровня, но перед заголовком пакета третьего уровня; в поле Flow Label заголовка пакета IPv6 или в поле VCI ячейки ATM. Это позволяет внедрить технологию Tag Switching практически в любую среду передачи данных.
Алгоритм обмена меток реализован следующим образом. После поступления пакета с меткой на очередной TSR, он считывает ее и использует как индекс поиска в своей базе данных меток (Tag Information Database, TIB). Каждой входной метке в TIB соответствует определенная информация, которая и используется для маршрутизации всех пакетов с этими метками.
Процедура поиска информации, необходимой для принятия решения о маршрутизации, в базе TIB эффективнее, чем в случае традиционного алгоритма поиска в обычной таблице маршрутизации. Кроме того, данная процедура может быть реализована на аппаратном уровне, используя технологию ASIC. Технология обработки меток не зависит от их назначения, то есть метка может соответствовать одному маршруту или совокупности маршрутов( в случае обычного трафика), маршруту группового трафика или идентификатору потока данных.
Решение Cisco Tag Switching позволяет резко уменьшить количество трубующейся информации о маршрутизации, так как только граничным TSR необходима вся информация от протоколов маршрутизации класса BGP( протокол граничной маршрутизации между автономными системами, или совокупности доменов маршрутизации, в сети Internet). С этой целью метод Cisco
Tag Switching предусматривает возможность включения в пакет не одной метки, а набора (стека) меток.MPLS (Multiprotocol Label Switching) — это технология быстрой коммутации пакетов в многопротокольных сетях, основанная на использовании меток. MPLS разрабатывается и позиционируется как способ построения высокоскоростных IP-магистралей, однако область ее применения не ограничивается протоколом IP, а распространяется на трафик любого маршрутизируемого сетевого протокола
.За развитие архитектуры MPLS отвечает рабочая группа с одноименным названием, входящая в секцию по маршрутизации консорциума IETF. В деятельности группы принимают активное участие представители крупнейших поставщиков сетевых решений и оборудования. В архитектуре MPLS собраны наиболее удачные элементы всех упомянутых разработок, и вскоре она должна превратиться в стандарт Internet благодаря усилиям IETF и компаний, заинтересованных в скорейшем продвижении данной технологии на рынок.
В основе MPLS лежит принцип обмена меток. Любой передаваемый пакет ассоциируется с тем или иным классом сетевого уровня (Forwarding Equivalence Class, FEC), каждый из которых идентифицируется определенной меткой. Значение метки уникально лишь для участка пути между соседними узлами сети MPLS, которые называются также
маршрутизаторами, коммутирующими по меткам (Label Switching Router, LSR). Метка передается в составе любого пакета, причем способ ее привязки к пакету зависит от используемой технологии канального уровня.Маршрутизатор LSR получает топологическую информацию о сети, участвуя в работе алгоритма маршрутизации — OSPF.BGP, IS-IS. Затем он начинает взаимодействовать с соседними маршрутизаторами, распределяя метки, которые в дальнейшем будут применяться для коммутации. Обмен метками может производиться с помощью как специального протокола распределения меток (Label Distribution Protocol, LDP), так и модифицированных версий других протоколов сигнализации в сети (например, незначительно видоизмененных протоколов маршрутизации, резервирования ресурсов RSVP и др.).
Распределение меток между LSR приводит к установлению внутри домена MPLS путей с коммутацией по меткам (Label Switching Path, LSP). Каждый маршрутизатор LSR содержит таблицу, которая ставит в соответствие паре “входной интерфейс, входная метка” тройку “префикс адреса получателя, выходной интерфейс, выходная метка”. Получая пакет, LSR пo номеру интерфейса, на который пришел пакет, и по значению привязанной к пакету метки определяет для него выходной интерфейс. (Значение префикса применяется лишь для построения таблицы и в самом процессе коммутации не используется.) Старое значение метки заменяется новым, содержавшимся в поле “выходная метка” таблицы, и пакет отправляется к следующему устройству на пути LSP.
Вся операция требует лишь одноразовой идентификации значений полей в одной строке таблицы. Это занимает гораздо меньше времени, чем сравнение IP-адреса отправителя с наиболее длинным адресным префиксом в таблице маршрутизации, которое используется при традиционной маршрутизации.
|
Приемущества технологии MPLS
|
Сеть MPLS делится на две функционально различные области —ядро и граничную область (рис. 1). Ядро образуют устройства,минимальным требованием к которым является поддержка MPLS и участие в процессе маршрутизации графика для того протокола,который коммутируется с помощью MPLS. Маршрутизаторы ядразанимаются только коммутацией. Все функции классификации пакетов по различным FEC, а также реализацию таких дополнительных сервисов, как фильтрация, явная маршрутизация, выравнивание нагрузки и управление графиком, берут на себя граничные LSR. В результате интенсивные вычисления приходятся на граничную область, а высокопроизводительная коммутация выполняется в ядре, что позволяет оптимизировать конфигурацию устройств MPLS в зависимости от их местоположения в сети. Таким образом, главная особенность MPLS — отделение процесса коммутации пакета от анализа IP-адресов в его заголовке, что открывает ряд привлекательных возможностей. Очевидным следствием описанного подхода является тот факт, что очередной сегмент LSP может не совпадать с очередным сегментом маршрута, который был бы выбран при традиционной маршрутизации. Поскольку на установление соответствия пакетов определенным классам FEC могут влиять не только IP-адреса, но и другие параметры, нетрудно реализовать, например, назначение различных LSP пакетам, относящимся к различным потокам RSVP или имеющим разные приоритеты обслуживания. Конечно, подобный сценарий удается осуществить и в обычных маршрутизируемых сетях, но решение на базе MPLS оказывается проще и к тому же гораздо лучше масштабируется . |
Каждый из классов FEC обрабатывается отдельно от остальных — не только потому, что для него строится свой путь LSP, но и в смысле доступа к общим ресурсам (полосе пропускания канала и буферному пространству). В результате технология MPLS позволяет очень эффективно поддерживать требуемое качество обслуживания, не нарушая предоставленных пользователю гарантий. Применение в LSR таких механизмов управления буферизацией и очередями, как WRED, WFQ или CBWFQ, дает возможность оператору сети MPLS контролировать распределение ресурсов и изолировать трафик отдельных пользователей.
Использование явно задаваемого маршрута в сети MPLS свободно от недостатков стандартной IP-маршрутизации от источника, поскольку вся информация о маршруте содержится в метке и пакету не требуется нести адреса промежуточных узлов, что улучшает управление распределением нагрузки в сети.
Метка — это короткий идентификатор фиксированной длины, который определяет класс FEC. По значению метки пакета определяется его принадлежность к определенному классу на каждом из участков коммутируемого маршрута.
Как уже отмечалось, метка должна быть уникальной лишь в пределах соединения между каждой парой логически соседних LSR. Поэтому одно и то же ее значение может использоваться LSR для связи с различными соседними маршрутизаторами, если только имеется возможность определить, от какого из них пришел пакет с данной меткой. Другими словами, в соединениях “точка—точка” допускается применять один набор меток на интерфейс, а для сред с множественным доступом необходим один набор меток на модуль или все устройство. В реальных условиях угроза исчерпания пространства меток очень маловероятна.
Перед включением в состав пакета метка определенным образом кодируется. В случае использования протокола IP она помещается в специальный “тонкий” заголовок пакета, инкапсулирующего IP. В других ситуациях метка записывается в заголовок протокола канального уровня или кодируется в виде определенного значения VPI/VCI (в сети АТМ). Для пакетов протокола IPv6 метку можно разместить в поле идентификатора потока.
В рамках архитектуры MPLS вместе с пакетом разрешено передавать не одну метку, а целый их стек. Операции добавления/изъятия метки определены как операции на стеке (push/pop). Результат коммутации задает лишь верхняя метка стека, нижние же передаются прозрачно до операции изъятия верхней.
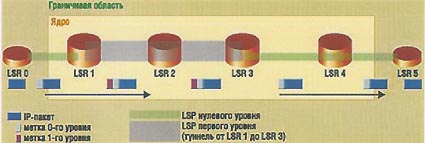
Такой подход позволяет создавать иерархию потоков в сети MPLS и организовывать туннельные передачи. Стек состоит из произвольного числа элементов, каждый из которых имеет длину 32 бита: 20 бит составляют собственно метку, 8 отводятся под счетчик времени жизни пакета, один указывает на нижний предел стека, а три не используются. Метка может принимать любое значение, кроме нескольких зарезервированных. Коммутируемый путь (LSP) одного уровня состоит из последовательного набора участков, коммутация на которых происходит с помощью метки данного уровня (рис. 2). Например, LSP нулевого уровня проходит через устройства LSR 0, LSR 1, LSR 3, LSR 4 и LSR 5. При этом LSR 0 и LSR 5 являются, соответственно, входным (ingress) и выходным (egress) маршрутизаторами для пути нулевого уровня. LSR 1 и LSR 3 играют ту же роль для LSP первого уровня
; первый из них производит операцию добавления метки в стек, а второй — ее изъятия. С точки зрения графика нулевого уровня, LSP первого уровня является прозрачным туннелем. В любом сегменте LSP можно выделить верхний и нижний LSR по отношению к графику. Например, для сегмента “LSR 4 — LSR 5” четвертый маршрутизатор будет верхним, а пятый — нижним.
Рис. 2 Компоненты коммутируемого соединения
Под привязкой понимают соответствие между определенным классом FEC и значением метки для данного сегмента LSP. Привязку всегда осуществляет “нижний” маршрутизатор LSR, поэтому и информация о ней распространяется только в направлении от нижнего LSR к верхнему. Вместе с этими сведениями могут предаваться атрибуты привязки.
Обмен информацией о привязке меток и атрибутах осуществляется между соседними LSR с помощью протокола распределения меток. Архитектура MPLS не зависит от конкретного протокола, поэтому в сети могут применяться разные протоколы сетевой сигнализации. Очень перспективно в данном отношении — использование RSVP для совмещения резервирования ресурсов и организации LSP для различных потоков.
Существуют два режима распределения меток: независимый и упорядоченный. Первый предусматривает возможность уведомления верхнего узла о привязке до того, как конкретный LSR получит информацию о привязке для данного класса от своего нижнего соседа. Второй режим разрешает высылать подобное уведомление только после получения таких сведений от нижнего LSR, за исключением случая, когда маршрутизатор LSR является выходным для этого FEC.
Распространение информации о привязке может быть инициировано запросом от верхнего устройства LSR (downstream on-demand) либо осуществляться спонтанно (unsolicited downstream).
Сначала посредством многоадресной рассылки сообщений UDP коммутирующие маршрутизаторы определяют свое “соседство” (adjacency). Кроме близости на канальном уровне, LSR могут устанавливать связь между “логически соседними” LSR, не принадлежащими к одному каналу. Это необходимо для реализации туннельной передачи. После того как соседство установлено, LSR определяет маршрут, по которому должно быть установлено соединение и начинает процедуру установки. От узла к узлу передаются запросы на привязку и собственно привязки соединений MPLS. После того как соединение было успешно установлено, источник периодически отправляет сообщения keepalive, информируя все транзитные LSR о том что соединение еще не разорвано.